
Week 7 — Outlier, prediction, & classification
Classification

- Classifies data (= constructs a model) based on the training set and the class labels and uses it in classifying new data. Steps for classification:
- Model construction (learning)-each instance is assumed to belong to a predefined class, called the class label, as determined by one of the attributes -set of all instances used to construct the model is called the training set -model is usually represented as if-then rules, decision trees or mathematical formulae
- Model evaluation (accuracy)-estimate accuracy of the model based on a test set -the known label of test sample is compared to the classified result from the model -accuracy = percentage of test set samples correctly classified by the model -test set must be independent of the training set otherwise over-fitting will occur (and the estimated accuracy will be too high)
- Model use (classification)-model is used to classify unseen instances (i.e. assigning class labels)
Training and testing data
Classification Methods
- Decision tree induction •Bayesian classification •Nearest neighbour classification, case-based reasoning (lazy learning) •Neural networks •Support Vector Machines •Ensemble methods
- Artificial intelligence is the theoretical concept “smart” or “sentiment” pandora box
- Deep learning — subfield of Machine learning inspired by brain structure/pattern. ‘Deep’ refers to the number of layers through which data is transferred. Such as computer vision, speech recognition, NLP (Natural learning processing), and self-car driving TESLA.
Supervised Learning:
1. Input data is labelled.
2. Uses a training data set.
3. Used for analysis.
4. Enables Classification, Density Estimation, & Dimension Reduction
Unsupervised Learning:
- Input data is unlabelled.
- Uses the input data set.
- Used for prediction.
- Enables classification and regression.
Steps of identifying data outlier:
- Identify the problem then gather
- Select ML model based on the problem
- Train our model on the training data
- Test our model to optimize
- Launch it to the test data

Data Cleansing
Need to preprocess the data to reduce noise by handling missing values, remove irrelevant or redundant attributes, then we can transform the data by evaluating by classification and prediction:

Decision Trees
- ID3 (Quinlan, 1986, UTS direct link)
- Entropy and information gain


- CART (Classification and regression Trees)
- Hypothesis space search and inductive bias
It is also refer to greedy search; meaning all the possible trees are searching until complete and represent all the possible hypotheses! - avoiding overfitting of training data
- handling continuous data
- very practical and widely used for ML method
- builds trees to translate into rules
- robust to noisy data
- Inductive bias prefers small trees over larger.
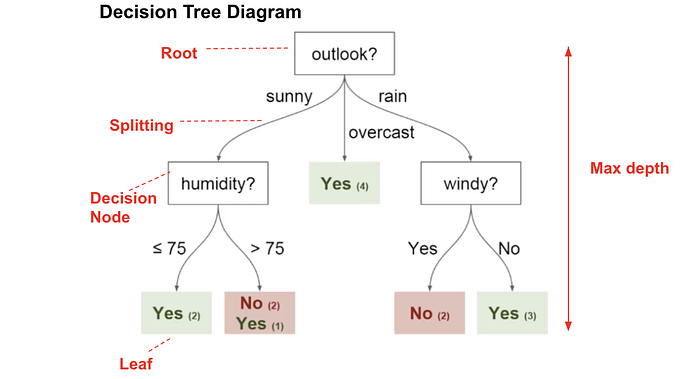
Humidity is the first attributes in the decision tree! Algorithms
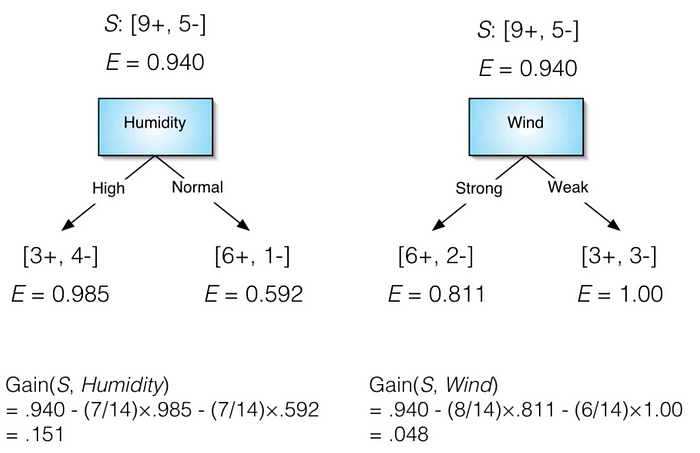
Interpretation: From the calculation of entropy, we got 9 days play tennis and 5 days we are not playing. 7 DAYS WITH HIGH HUMIDITY AND 3 DAYS WITH STRONG WIND. S has 14 examples, 9 positive and 5 negative.
Formula on the bottom : Entropy x the proportion of normal — (the proportion of high humidity x entropy of normal humidity).
Backlash with decision tree:
Inductive bias — prefer trees with high attribute, prefer short/simple decision tree. Scientists work in mimics the deep philosophical question.
- Avoid overfitting training data
Overfitting is a modeling error that occurs when a function is too closely fit to a limited set of data points. Overfitting the model generally takes the form of making an overly complex model to explain idiosyncrasies in the data under study.Dividing the data.
How to divide the data:
Training set — is used to build the initial model • may need to “enrich the data” to get enough of the special cases • to train the decision tree
Cross validation set — is used to adjust the initial model • used to work out the correct values of parameters in model • models can be tweaked to be less dependent on idiosyncrasies in the training data to be a more general model • idea is to prevent ‘over-training’ (i.e. finding patterns where none exist) • for deciding when to prune
Test set — is used to evaluate the model performance. Should not be used in training the model. • for estimating the error on the unseen data
How to Overfitting training data?
- Stop growing the tree once the test error decreases
- Grow the tree as normal (i.e with overfitting), and then post-prune
How to determine the right tree size?
- Use a separate set of data apart from training to test when to prune nodes (training and cross validation set)
- Use all data to train, but apply a statistical test whether to expand or prune a node
- Use an explicit complexity measure (i.e Minimum description length principle)
Online learning platforms are: courser, edx, Udemy, Future learn and Udacity
2. Rule post-pruning
Pruning = remove subtree, make into a leaf, assign label as most common class in associated training examples.

if (Outlook = Sunny) and (Humidity = High) then PlayTennis = No
3. Continuous valued variable
4. Confusion matrix
Identifier also use
